SpatialGrammar: A Domain-Specific Language for LLM-Based 3D Indoor Scene Generation

Abstract
Automatically generating interactive 3D indoor scenes from natural language is crucial for virtual reality, gaming, and embodied AI. However, existing LLM-based approaches often suffer from spatial errors and collisions, in part because common scene representations—raw coordinates or verbose code—are difficult for models to reason about 3D spatial relationships and physical constraints. We propose SpatialGrammar, a domain-specific language that represents gravity-aligned indoor layouts as BEV grid placements with deterministic compilation to valid 3D geometry, enabling verifiable constraint checking. Building on this representation, we develop (1) SG-Agent, a closed-loop system that uses compiler feedback to iteratively refine scenes and enforce collision constraints, and (2) SG-Mini, a 104M-parameter model trained entirely on compiler-validated synthetic data. On our benchmark, SG-Agent improves spatial fidelity and physical plausibility over prior methods, while SG-Mini matches or exceeds several larger LLM-based baselines under the same evaluation settings.
Method Overview
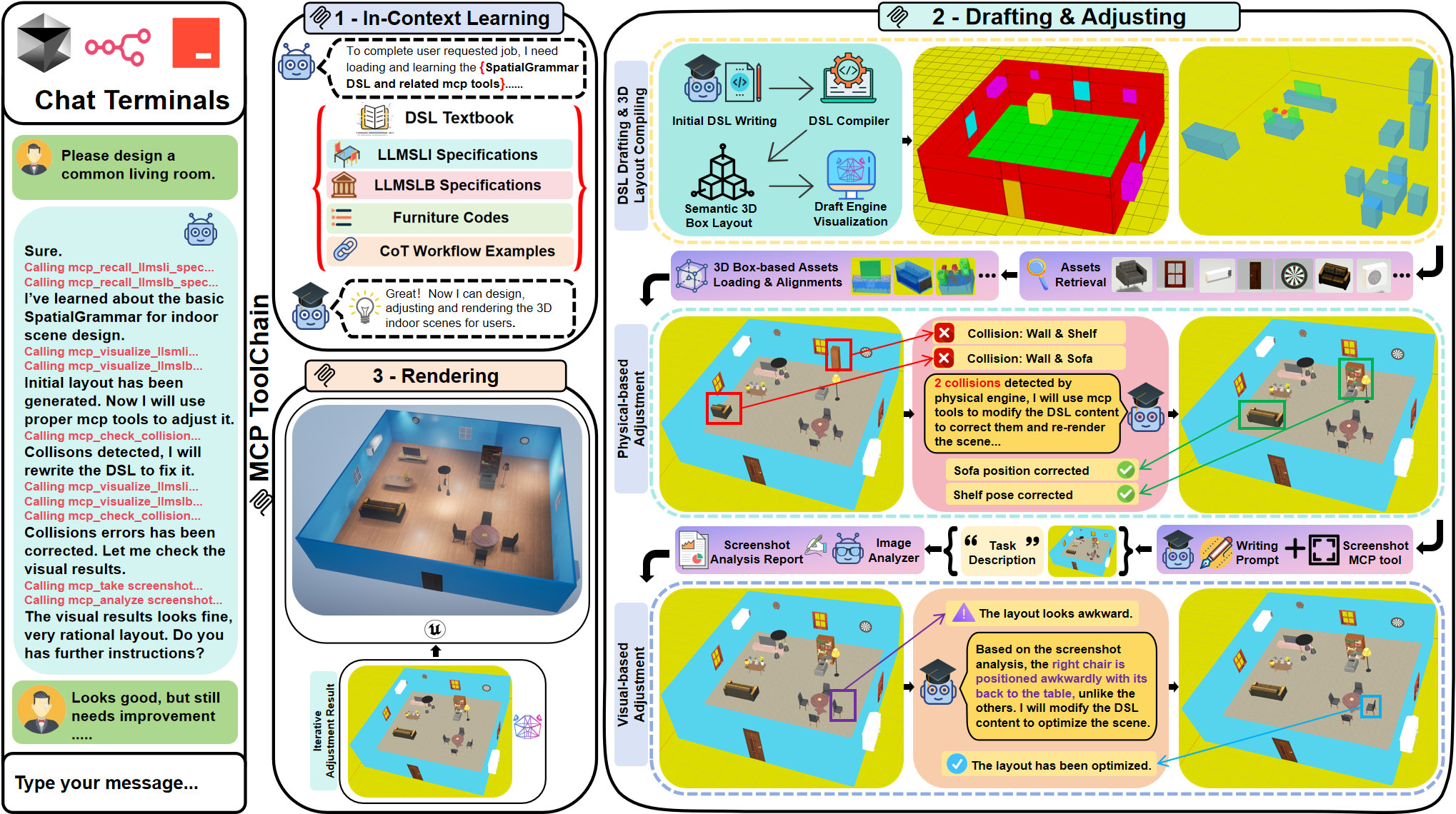
Overview of the SpatialGrammar agentic workflow. A user issues a request, then the agent consults the DSL textbook, writes an initial SpatialGrammar script, and calls the compiler to obtain a semantic 3D box layout. After asset retrieval, the layout is loaded into the Draft Engine for real-time visualization, physics-based collision checks, and screenshots for multimodal analysis. The agent iteratively edits the DSL based on symbolic and visual feedback until the scene is satisfactory.
SpatialGrammar encodes physical priors directly into the representation through three components: (1) SpatialGrammar Language — abstracts 6-DoF pose generation into a 2D BEV grid, where the LLM places objects on discrete cells with yaw-only rotation and the compiler deterministically recovers precise 3D poses. Hierarchical sub-layouts handle complex arrangements (tabletops, wall-mounted items) via face-anchored local frames. (2) SG-Agent — a closed-loop system where the compiler and Draft Engine provide symbolic collision feedback and visual rendering; the agent iteratively refines the DSL until the scene is collision-free, typically in 2–3 iterations. (3) SG-Mini — a 104M-parameter model trained entirely on compiler-validated synthetic data (pre-training → SFT → DPO), matching or exceeding larger LLM baselines without human annotation.
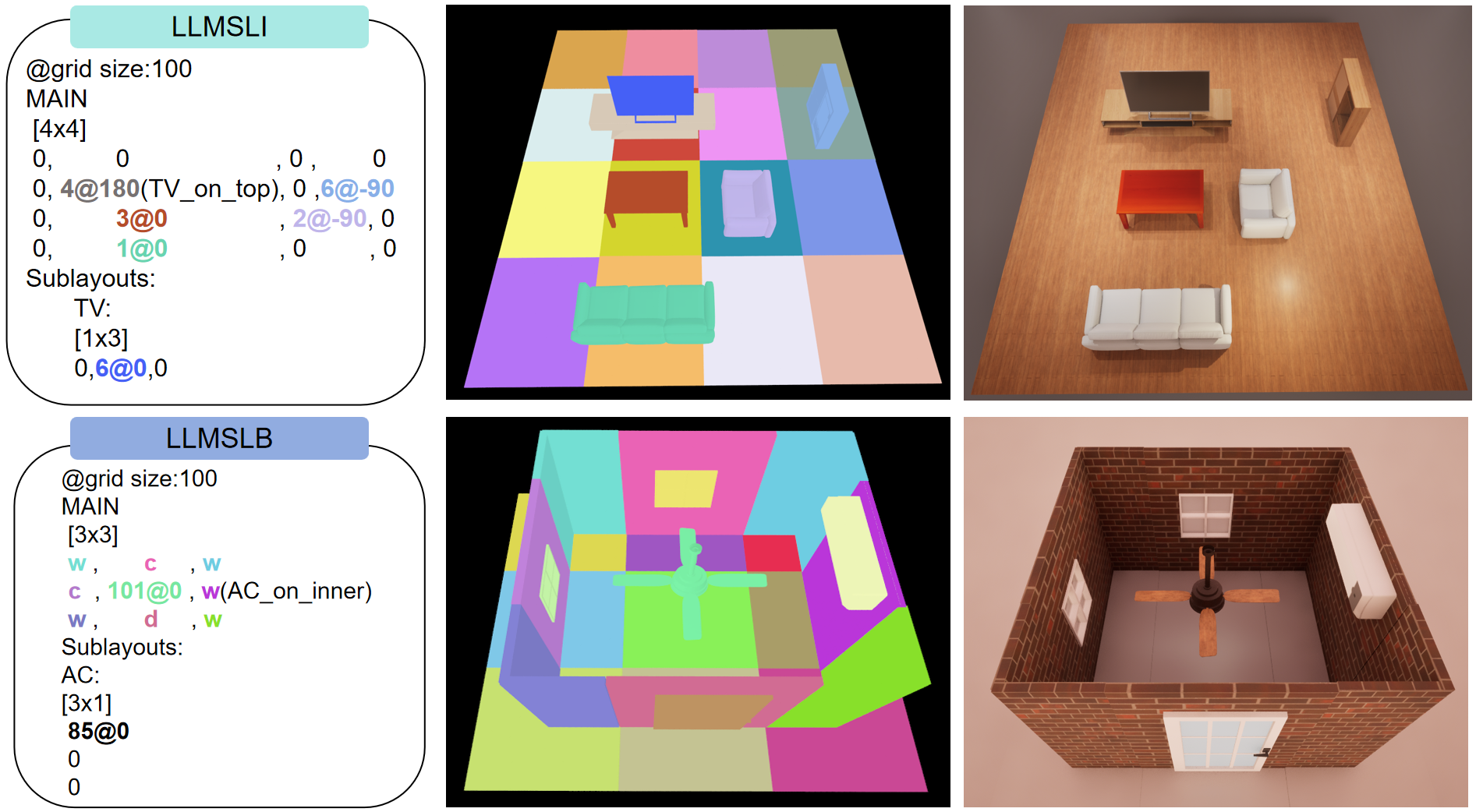
DSL code (left), semantic intermediate representation (middle), and final render (right).
BibTeX
@article{tang2026spatialgrammar,
title={SpatialGrammar: A Domain-Specific Language for LLM-Based 3D Indoor Scene Generation},
author={Tang, Song and Zhao, Kaiyong and Li, Yuliang and Yan, Qingsong and Sun, Penglei and Zou, Junyi and Wang, Qiang and Chu, Xiaowen},
year={2026}
}